前情提要:
上一篇主要介紹了邏輯回歸中,相對理論化的知識,這次主要是對上篇做一點點補充,以及介紹sklearn 邏輯回歸模型的參數,以及具體的實戰代碼。
1.邏輯回歸的二分類和多分類
上次介紹的邏輯回歸的內容,基本都是基於二分類的。那麼有沒有辦法讓邏輯回歸實現多分類呢?那肯定是有的,還不止一種。
實際上二元邏輯回歸的模型和損失函數很容易推廣到多元邏輯回歸。比如總是認為某種類型為正值,其餘為0值。
舉個例子,要分類為A,B,C三類,那麼就可以把A當作正向數據,B和C當作負向數據來處理,這樣就可以用二分類的方法解決多分類的問題,這種方法就是最常用的one-vs-rest,簡稱OvR。而且這種方法也可以方便得推廣到其他二分類模型中(當然其他算法可能有更好的多分類辦法)。
另一種多元邏輯回歸的方法是Many-vs-Many(MvM),它會選擇一部分類別的樣本和另一部分類別的樣本來做邏輯回歸二分類。
聽起來很不可思議,但其實確實是能辦到的。比如數據有A,B,C三個分類。
我們將A,B作為正向數據,C作為負向數據,訓練出一個分模型。再將A,C作為正向數據,B作為負向數據,訓練出一個分類模型。最後B,C作為正向數據,C作為負向數據,訓練出一個模型。
通過這三個模型就能實現多分類,當然這裏只是舉個例子,實際使用中有其他更好的MVM方法。限於篇幅這裏不展開了。
MVM中最常用的是One-Vs-One(OvO)。OvO是MvM的特例。即每次選擇兩類樣本來做二元邏輯回歸。
對比下兩種多分類方法,通常情況下,Ovr比較簡單,速度也比較快,但模型精度上沒MvM那麼高。MvM則正好相反,精度高,但速度上比不過Ovr。
2.邏輯回歸的正則化
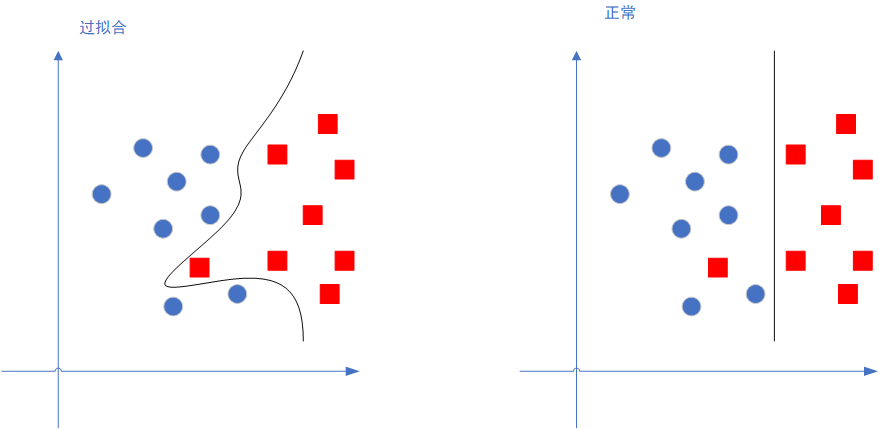
所謂正則化,其目的是為了減弱邏輯回歸模型的精度,難道模型的準確度不是越高越好嘛?看看下面這張圖就明白了:
左邊那個圖就是過擬合的情況,過擬合其實就是模型的精度太過高了,它能非常好得匹配訓練集的數據,但一旦有新的數據,就會表現得很差。
而我們要的非過擬合的模型是,精度可以差一些,但泛化性能,也就是對新的數據的識別能力,要比較好。
正則化就是減弱模型精度,提高泛化效果的這個東西。
3.sklearn各個參數
def LogisticRegression(penalty='l2',
dual=False,
tol=1e-4,
C=1.0,
fit_intercept=True,
intercept_scaling=1,
class_weight=None,
random_state=None,
solver='warn',
max_iter=100,
multi_class='warn',
verbose=0,
warm_start=False,
n_jobs=None,
l1_ratio=None
)
跟線性回歸一比,邏輯回歸的參數那還真是多啊,不過我們一個一個來看看參數都是什麼意思吧。
- dual:對偶或者原始方法,布爾類型,默認為False。Dual只適用於正則化相為l2的‘liblinear’的情況,通常樣本數大於特徵數的情況下,默認為False。
- tol:停止迭代求解的閾值,單精度類型,默認為1e-4。
- C:正則化係數的倒數,必須為正的浮點數,默認為 1.0,這個值越小,說明正則化效果越強。換句話說,這個值越小,越訓練的模型更泛化,但也更容易欠擬合。
- fit_intercept:是否要使用截距(在決策函數中使用截距),布爾類型,默認為True。
- intercept_scaling:官方解釋比較模糊,我說下個人理解。浮點型,默認值是1.0。這個參數僅在“solver”參數(下面介紹)為“liblinear”“fit_intercept ”參數為True的時候生效。作用是給特徵向量添加一個常量,這個常量就是intercept_scaling。比如原本的向量是[x],那麼添加后就變成[x,intercept_scaling]。
- class_weight:分類權重,可以是一個dict(字典類型),也可以是一個字符串"balanced"字符串。默認是None,也就是不做任何處理,而"balanced"則會去自動計算權重,分類越多的類,權重越低,反之權重越高。也可以自己輸出一個字典,比如一個 0/1 的二元分類,可以傳入{0:0.1,1:0.9},這樣 0 這個分類的權重是0.1,1這個分類的權重是0.9。這樣的目的是因為有些分類問題,樣本極端不平衡,比如網絡攻擊,大部分正常流量,小部分攻擊流量,但攻擊流量非常重要,需要有效識別,這時候就可以設置權重這個參數。
- random_state:設置隨機數種子,可以是int類型和None,默認是None。當"solver"參數為"sag"和"liblinear"的時候生效。
- verbose:輸出詳細過程,int類型,默認為0(不輸出)。當大於等於1時,輸出訓練的詳細過程。僅當"solvers"參數設置為"liblinear"和"lbfgs"時有效。
- warm_start:設置熱啟動,布爾類型,默認為False。若設置為True,則以上一次fit的結果作為此次的初始化,如果"solver"參數為"liblinear"時無效。
- max_iter:最大迭代次數,int類型,默認-1(即無限制)。注意前面也有一個tol迭代限制,但這個max_iter的優先級是比它高的,也就如果限制了這個參數,那是不會去管tol這個參數的。
OK,上述就是對一些比較簡略的參數的說明,但是還有幾個重要的參數沒講到,這是因為這幾個參數我覺得需要單獨拎出來講一講。
sklearn邏輯回歸參數 –penalty
正則化類型選擇,字符串類型,可選’l1’,’l2’,’elasticnet’和None,默認是’l2’,通常情況下,也是選擇’l2’。這個參數的選擇是會影響到參數’solver’的選擇的,下面會介紹。
其中’l1’和’l2’。分別對應L1的正則化和L2的正則化,’elasticnet’則是彈性網絡(這玩意我也不大懂),默認是L2的正則化。
在調參時如果主要的目的只是為了解決過擬合,一般penalty選擇L2正則化就夠了。但是如果選擇L2正則化發現還是過擬合,即預測效果差的時候,就可以考慮L1正則化。另外,如果模型的特徵非常多,我們希望一些不重要的特徵係數歸零,從而讓模型係數稀疏化的話,也可以使用L1正則化。
penalty參數的選擇會影響我們損失函數優化算法的選擇。即參數solver的選擇,如果是L2正則化,那麼4種可選的算法{‘newton-cg’,‘lbfgs’,‘liblinear’,‘sag’}都可以選擇。但是如果penalty是L1正則化的話,就只能選擇‘liblinear’了。這是因為L1正則化的損失函數不是連續可導的,而{‘newton-cg’,‘lbfgs’,‘sag’}這三種優化算法時都需要損失函數的一階或者二階連續導數。而‘liblinear’並沒有這個依賴。最後還有一個’elasticnet’,這個只有solver參數為’saga’才能選。
sklearn邏輯回歸參數 –solver
優化算法參數,字符串類型,一個有五種可選,分別是”newton-cg”,”lbfgs”,”liblinear”,”sag”,”saga。默認是”liblinear”。分別介紹下各個優化算法:
- a) liblinear:使用了開源的liblinear庫實現,內部使用了坐標軸下降法來迭代優化損失函數。
- b) lbfgs:擬牛頓法的一種,利用損失函數二階導數矩陣即海森矩陣來迭代優化損失函數。
- c) newton-cg:也是牛頓法家族的一種,利用損失函數二階導數矩陣即海森矩陣來迭代優化損失函數。
- d) sag:即隨機平均梯度下降,是梯度下降法的變種,和普通梯度下降法的區別是每次迭代僅僅用一部分的樣本來計算梯度,適合於樣本數據多的時候。
在優化參數的選擇上,官方是這樣建議的: - e)saga:優化的,無偏估計的sag方法。(‘sag’ uses a Stochastic Average Gradient descent, and ‘saga’ uses its improved, unbiased version named SAGA.)
對小的數據集,可以選擇”liblinear”,如果是大的數據集,比如說大於10W的數據,那麼選擇”sag”和”saga”會讓訓練速度更快。
對於多分類問題,只有newton-cg,sag,saga和lbfgs能夠處理多項損失(也就是MvM的情況,還記得上面說到的多分類嘛?),而liblinear僅處理(OvR)的情況。啥意思,就是用liblinear的時候,如果是多分類問題,得先把一種類別作為一個類別,剩餘的所有類別作為另外一個類別。一次類推,遍歷所有類別,進行分類。
這個的選擇和正則化的參數也有關係,前面說到”penalty”參數可以選擇”l1″,”l2″和None。這裏’liblinear’是可以選擇’l1’正則和’l2’正則,但不能選擇None,’newton-cg’,’lbfgs’,’sag’和’saga’這幾種能選擇’l2’或no penalty,而’saga’則能選怎’elasticnet’正則。好吧,這部分還是挺繞的。
歸納一下吧,二分類情況下,數據量小,一般默認的’liblinear’的行,數據量大,則使用’sag’。多分類的情況下,在數據量小的情況下,追求高精度,可以用’newton-cg’或’lbfgs’以’MvM’的方式求解。數據量一大還是使用’sag’。
當然實際情況下還是要調參多次才能確定參數,這裏也只能給些模糊的建議。
sklearn邏輯回歸參數 –multi_class
multi_class參數決定了我們分類方式的選擇,有 ovr和multinomial兩個值可以選擇,默認是 ovr。
ovr即前面提到的one-vs-rest(OvR),而multinomial即前面提到的many-vs-many(MvM)。如果是二元邏輯回歸,ovr和multinomial並沒有任何區別,區別主要在多元邏輯回歸上。
4.sklearn實例
實例這部分,就直接引用sklearn官網的,使用邏輯回歸對不同種類的鳶尾花進行分類的例子吧。
import numpy as np
import matplotlib.pyplot as plt
from sklearn import linear_model, datasets
# 加載鳶尾花數據
iris = datasets.load_iris()
# 只採用樣本數據的前兩個feature,生成X和Y
X = iris.data[:, :2]
Y = iris.target
h = .02 # 網格中的步長
# 新建模型,設置C參數為1e5,並進行訓練
logreg = linear_model.LogisticRegression(C=1e5)
logreg.fit(X, Y)
# 繪製決策邊界。為此我們將為網格 [x_min, x_max]x[y_min, y_max] 中的每個點分配一個顏色。
x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5
y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
Z = logreg.predict(np.c_[xx.ravel(), yy.ravel()])
# 將結果放入彩色圖中
Z = Z.reshape(xx.shape)
plt.figure(1, figsize=(4, 3))
plt.pcolormesh(xx, yy, Z, cmap=plt.cm.Paired)
# 將訓練點也同樣放入彩色圖中
plt.scatter(X[:, 0], X[:, 1], c=Y, edgecolors='k', cmap=plt.cm.Paired)
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.xticks(())
plt.yticks(())
plt.show()運行上面那段代碼會有如下的結果:
可以看到,已將三種類型的鳶尾花都分類出來了。
小結
邏輯回歸算是比較簡單的一種分類算法,而由於簡單,所以也比較適合初學者初步接觸機器學習算法。學習了之後,對後面一些更複雜的機器學習算法,諸如Svm,或更高級的神經網絡也能有一個稍微感性的認知。
而實際上,Svm可以看作是邏輯回歸的更高級的演化。而從神經網絡的角度,邏輯回歸甚至可以看作一個最初級,最淺層的神經網絡。
邏輯回歸就像是金庸小說裏面,獨孤九劍的第一式,最為簡單,卻又是其他威力極大的招式的基礎,其他的招式都又第一式演化而出。
夯實基礎,才能砥礪前行。
以上~
參考文章:
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※評比前十大台北網頁設計、台北網站設計公司知名案例作品心得分享
※智慧手機時代的來臨,RWD網頁設計已成為網頁設計推薦首選
※評比南投搬家公司費用收費行情懶人包大公開
※幫你省時又省力,新北清潔一流服務好口碑